(Left to right): Original scene, Texture reconstruction in context, Texture reconstruction, Pose reconstruction
Abstract
We present a method to build animatable dog avatars from monocular videos.
This is challenging as animals display a range of (unpredictable) non-rigid movements and have a variety of appearance details (e.g., fur, spots, tails). We develop an approach that links the video frames via a 4D solution that jointly solves for animal's pose variation, and its appearance (in a canonical pose).
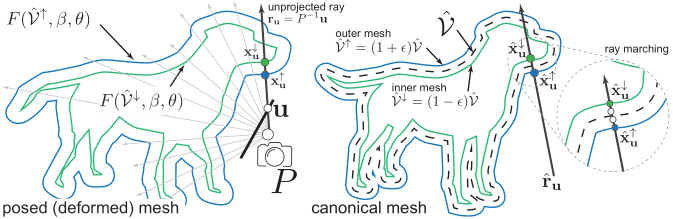
To this end, we significantly improve the quality of template-based shape fitting by endowing the SMAL parametric model with Continuous Surface Embeddings (CSE), which brings image-to-mesh reprojection constaints that are denser, and thus stronger, than the previously used sparse semantic keypoint correspondences. To model appearance, we propose an implicit duplex-mesh texture that is defined in the canonical pose, but can be deformed using SMAL pose coefficients and later rendered to enforce a photometric compatibility with the input video frames . On the challenging CoP3D dataset, we demonstrate superior results (both in terms of pose estimates and predicted appearance) to existing template-free (RAC) and template-based approaches (BARC, BITE).

Input Signal
Traditional solutions used mainly only sparse keypoints. However, the training of these keypoint predictors is biased toward front-facing views. As a result. we observe few keypoints on frame of the video where the dog is filmed from behind. In contrast, CSE embeddings (3rd column from left) on which our method relies, provide a dense signal regardless of the viewpoint.
Our solution leverages (left to right): image, mask, dense correspondences and sparse keypoints
Qualitative comparison: Pose
We compare our pose reconstruction on a set of videos from the COP3D dataset. First, we compare to BARC and BITE. Similarly to us, they are template-based models, based on SMAL. However, they take as input only a single frame. Additionaly, we evaluate on RAC, a template-free reconstructor predicting shape (and texture) from input videos. We observe that:
- Since they predict shape independently between frames, BARC & BITE prediction is flickering and inconsistent in time
- The shape reconstruction from RAC is very poor and unrealistic compared to the other template-based approaches (including our). This prevents any possible reanimation of the reconstructed avatar.
Pose prediction (Left to right): Our, BARC, BITE, RAC.
Qualitative comparison: Texture
In this project we introduced the canonical duplex-mesh renderer, a new deformable implicit shape model. We evaluate the quality of texture reconstruction on the same models from shape evaluation. We compare to RAC, since BARC and BITE only provide shape reconstruction with no texture. We observe that:
- Our canonical duplex-mesh renderer provide detailed texture over the mesh
- The quality of our texture reconstruction is superior compared to RAC over all the scenes.
Texture reconstruction (Left to right): Our, RAC.
Application: Avatar re-animation
Once an avatar (composed of a shape, time-dependent pose and texture) model is extracted from a scene, it can be animated via an other sequence of pose. Here, we animate a set of K=6 avatars with the same source dynamic motion, extracted from various scenes.
Avatar Reanimation (Left to right): Original scene, reconstructed avatar from scene, K=6 avatars with motion from scene
Related Work
- Rueegg, N., Zuffi, S., Schindler, K., & Black, M. J. (2022). BARC: Learning to Regress 3D Dog Shape from Images by Exploiting Breed Information. (link)
- Ruegg, N., Tripathi, S., Schindler, K., Black, M. J., & Zuffi, S. (2023). BITE: Beyond Priors for Improved Three-D Dog Pose Estimation. (link)
- Yang, G., Wang, C., Reddy, N. D., & Ramanan, D. (2023). Reconstructing Animatable Categories from Videos. (link)